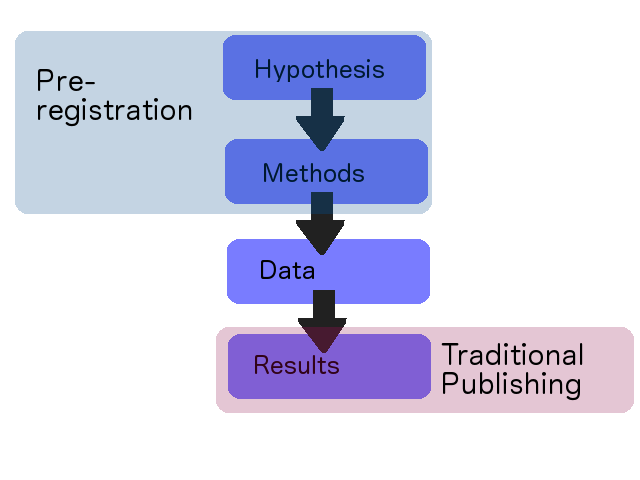
Methodological rigor has been the center of a growing debate in the behavioral and brain sciences. A big problem thus far is that we've largely only published
results. Preregistration forces us to publish
methods and hypotheses ahead of time, which can help with
p-value hacking, post-hoc storytelling and the
"file drawer" method for dealing with negative or unwanted results. Even prominent journals like
Cortex are getting in on
preregistration with a publication guarantee, effectively focusing peer review on methods and hypotheses and not on "interesting" results. Some journals also require
data sharing, including
Cortex in its new initiative, by uploading to public hosting services like
FigShare.
I want to go one step further and suggest that it's time to share
data, method and process. I want every box in that little chart covered, and moreover, I want to be able to look at how we get from box to box.
Preregistration is great and should help us to avoid a lot of post-hoc tomfoolery. But preregistration is difficult to use for certain types of exploratory or simulation-based research. While the reporting of incidental results are still allowed under certain forms of preregistration (including the
Cortex) model, purely exploratory studies, including iterative simulation development studies, don't fit in well with preregistration. The
Neuroskeptic agrees that such results don't fit the preregistration model per se, but should be marked as exploratory (perhaps implicitly via their missing registration) so that it's clear that any interesting patterns could be the result of careful selection:
We all know that any 1000C finding might be a picked cherry from a rich fruit basket.
By opening up process, we can still learn a lot about the fruit left in the basket.
The following is my proposal for a variant of preregistration compatible with exploratory and simulation-based research. It is based on open access and open source principles and will discourage the post-hoc practices that lead to unreliable results. The
key idea is transparency at every step -- making the context of an experiment and an analysis available and apparent not only encourages "honesty" of individual researchers in their claims but also allows us to get away from the binary world of "significance".
This is just an initial proposal, so I won't go into all the details and I am aware that there are a few kinks to work out.
Beyond Preregistration: Full Logging
My basic proposal is this: public, append-only tracking of research process and iteration via distributed version control systems like
Mercurial and
Git. In essence, this is a form of extensive, semi-automated logging / snapshotting. For the individual user, this also has the nice advantage of allowing you to go back in time to older versions, compare different versions, and even help track down inconsistencies between analyses.
The initial entry in the log should clearly state whether the study is confirmatory or exploratory. Simulatory or not is orthogonal to confirmatory/exploratory: if you're just testing whether a new model fits the data reasonably well, then you should define ahead of time what you mean by "reasonably well" and test that as you would any hypothesis in a real-world experimental investigation. If you're trying to develop a model/simulation in the first place and just want to see how good you can make it for the data at hand, then that is exploratory research and should be marked as such.
Texas sharp-shooting is just as problematic, if not more so, in simulation-based research as in research in the real world.
This should then dovetail nicely into a
Frontiers type publishing model with an iterative, interactive review. The review process would just be part of the log.
Context and Curiosity
A fundamental problem with our statistics is that we think in binary: "significant" or "not significant" and often completely ignore the context and assumptions of statistical tests. Even xkcd has touched upon the
many of the common issues in understanding statistics. Many issues arise from post-hoc thinking, and this is what preregistration tries to prevent.
Post-hoc thinking violates statistical assumptions. Odds are there are some interesting patterns in your data that occurred by chance. If you test them after you've already seen that they're there, then you're
begging the question. If you report that you found this pattern while doing something else, then it presents a direction for future research. But if you present that pattern as the one you were looking for all along, then you've violated the assumption of randomness that null hypothesis testing is based on.
By recording the little steps, we give our data the full context to understand and interpret them, even if they are "just" exploratory data. Exploratory data has a different context and it's the context we need to fully evaluate a result, and not some label like "significant".
Isaac Asimov supposedly once said that "The most exciting phrase to hear in science, the one that heralds new discoveries, is not 'Eureka' but 'That’s funny...'". Even if serendipitous success is the exception and not the rule, we need a forum to get all the data we have out in the open in a way that doesn't distort its meaning.
Some Details
The following gets a tad more technical, but should make my idea a bit more concrete. There are a lot more details that I have given serious thought to, but won't address here.
Implementation
More precisely, I'm suggesting something like
GitHub or
Bitbucket, but with the key difference that history is immutable and repositories cannot be deleted (to prevent ad-hoc mutation via deletion and recreation.) The preregistration component would be the initial commit, in which a README type document would outline the plan. For confirmatory research, this README would follow the same form as preregistration. (Indeed, the initial commit could even be done automatically following a traditional, web-based preregistration form.) For exploratory research (e.g. mining data corpora for interesting patterns as hints for planning confirmatory research), the README would be a description of the corpora (or a description of the planned corpora), including the planned size (i.e. test subjects and trials) of the corpus (optional stopping is bad). For simulation-based research, the README would include a description of the methodology for testing goodness of fit as well as an outline of the theoretical background being implemented computationally (lowering the bar of your model post hoc is bad). Exploratory dead ends would be apparent as unmerged branches.
As stated above, this should tie nicely into a Frontiers type publishing model with an iterative, interactive review. Publications coming from a particular experimental undertaking would have to be included in the repository (or a fork thereof if you're analyzing somebody else's data), which would make it clear when somebody's been double dipping as well as quickly giving an overview of all relevant publications. As part of this, all the scripts that go into generating figures should be present in the repository. This of course requires that you write a script for everything, even if it's just one line to document exactly what command-line options you gave.
The open repository nature also supports reproduciblity via extensive documentation/logging and openness of the original data. The latter is also important for "warm-ups" to confirmatory research: getting a good preregistration protocol outlined often requires playing with some existing data beforehand to work out kinks in the design. For exploratory and simulatory work, everything is documented: you know what was tried out, what did and didn't work, as well as both the results of statistical tests and their context, all of which is required to figure out useful future directions.
A Few Obvious Concerns
Now, there are a few obvious problems that we need to address now, despite me trying to avoid too many details.
- The log given by the full repository is far too big to be reviewed in its entirety. This is certainly true, but a full review should rarely be necessary, and the presence of such data would both discourage dishonesty as well as providing a better means to track it down. Of course, this is assuming that people publish the intermediate steps where data were falsified or distorted, but then again, the presence of large, opaque jumps in the log would also be an indicator of something odd going on. ("Jumps" in the logical sense and not necessarily in the temporal sense. Commit messages can and should provide additional context.) For more general perusal or tracking down a particular error source, there are many well-known methods for finding a particular entry -- and many of them are already part of both Mercurial and Git!
- Data often comes in large binary formats. I know, neither Mercurial nor Git do too well with large binary files; however, the original data files (measurements) should be immutable, which means that there will be no changes to track. Derived data files (e.g filtered data in EEG research, anything that can be generated from the original measurements) should not be tracked, but their creation should be trivial if all support scripts are included in the repository. This will also reduce the amount of data that has to be hosted somewhere.
- Even if we get people to submit to this idea, they can still lie by modifying history before pushing to the central repository. I don't have a full answer to this yet beyond "cheating is always possible, but this system should make it harder." Even under traditional preregistration, it's still possible to cheat by playing with time stamps on your files and preregistering afterwards. Non trivial, but possible. And so it is here. However, as pointed out above, the form of the record should also give some indication that something fishy is going on. Moreover, the initial commit reduces to traditional preregistration in the case of confirmatory research. Finally, this approach is about getting everything out in the sunlight; it does not guarantee publication, if for example, there is a fundamental flaw in your methodology. But the openness may allow somebody to comment and help you before you've gone too far off the path!
Open (for Comments)
More so than even with traditional preregistration, the system proposed above should encourage and enforce a radical openness in science. For the edge cases of preregistration (exploratory and simulatory work), you can avoid some of the rigidity of preregistation at a heavy price: everything is open and it is very clear that your data is exploratory and indeed it's clear when you found interesting data. It's clear when you find something after a long fishing expedition, which means it's clear that the result is to be taken with a grain of salt. But it also provides an unbelievably open format for showing people interesting patterns in the data, which potentially support existing research but also demand further investigation with a more focused experiment.